The Automation Testing System 3: Model-based Testing
The model-based testing system is a sub-project in zstack-woodpecker. With finite-state machines and action selection strategies, it can generate random API operations that may run forever unless a defect is found, or pre-defined exit conditions are met. ZStack relies on model-based testing to test corner cases that hardly happen in real world, which compensates integration testing and system testing in terms of test coverage.
Overview
Test coverage is an important indicator that judges the quality of a testing system. Regular testing methodologies such as unit testing, integration testing, and system testing all of which are designed by human logical thinking are very hard to cover corner cases of the software. This problem becomes more obvious in IaaS software that manage different sub-systems that can lead to complex scenarios.
ZStack solves this problem by introducing model-based testing that can generate scenarios consisting of random API combinations that will continuously run until meeting pre-defined exit conditions or finding a defect. As machine driven testing, the model-based testing can overcome weaknesses of human logical thinking to conduct tests that are seemly human illogical but API correct, helping discover corner cases that are hard to notice by human leading testing.
An example may help understand the idea; the model-based testing system used to uncover a bug after executing ~200 APIs; after debugging, we found the minimal sequence to reproduce the issue is:
- create a VM
- stop the VM
- create a volume snapshot for the VM's root volume
- create a new data volume template from the VM root volume
- destroy VM
- create a new data volume from the template in step 4
- create a new volume snapshot from the data volume in step 6
This operating sequence is apparently illogical, we believe no tester will write an integration testing case or system testing case doing so. This is where machine thinking shines because it doesn't have human feelings and will do things human feels unreasonable. After finding this bug, we generate a regression test to guard the issue for the future.
Model-based Testing System
The model-based testing system, as driven by the machine, is also called robot testing. When the system runs, it moves from one model(also called stage in following sections) to another by executing actions(also called operations) selected by action selection strategies. After every model is finished, checkers will validate the testing result and test exit conditions; the system will quit if any failure is discovered or the exit conditions are met. Otherwise, it moves to next model and repeats.
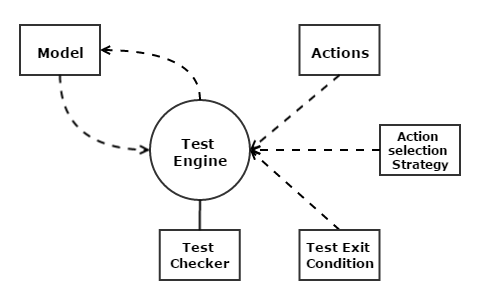
Finite-state Machine
In the theory of model-based testing, there are many ways to generate testing operations, for example, finite-state machine, theorem proving, model checking. We chose to use a finite-state machine because it naturally fits IaaS software that every resource is essentially driven by states. For example, VM states from user perspective are like:
![]()
In the model-based testing system, states of every resource are pre-defined in test_state.py, which looks like:
vm_state_dict = {
Any: 1 ,
vm_header.RUNNING: 2,
vm_header.STOPPED: 3,
vm_header.DESTROYED: 4
}
vm_volume_state_dict = {
Any: 10,
vm_no_volume_att: 20,
vm_volume_att_not_full: 30,
vm_volume_att_full: 40
}
volume_state_dict = {
Any: 100,
free_volume: 200,
no_free_volume:300
}
image_state_dict = {
Any: 1000,
no_new_template_image: 2000,
new_template_image: 3000
}States of all resources in the system make up of a stage(model); the system can transit from one stage to next stage by executing operations maintained in the transition table. A stage is defined as:
class TestStage(object):
'''
Test states definition and Test state transition matrix.
'''
def __init__(self):
self.vm_current_state = 0
self.vm_volume_current_state = 0
self.volume_current_state = 0
self.image_current_state = 0
self.sg_current_state = 0
self.vip_current_state = 0
self.sp_current_state = 0
self.snapshot_live_cap = 0
self.volume_vm_current_state = 0
...A stage can be represented by an integer that is the sum of all states the stage contains; using the integer, we can look up the transition table for next candidate operations; an example of the transition table is like:
#state transition table for vm_state, volume_state and image_state
normal_action_transition_table = {
Any: [ta.create_vm, ta.create_volume, ta.idel],
2: [ta.stop_vm, ta.reboot_vm, ta.destroy_vm, ta.migrate_vm],
3: [ta.start_vm, ta.destroy_vm, ta.create_image_from_volume, ta.create_data_vol_template_from_volume],
4: [],
211: [ta.delete_volume],
222: [ta.attach_volume, ta.delete_volume],
223: [ta.attach_volume, ta.delete_volume],
224: [ta.delete_volume],
232: [ta.attach_volume, ta.detach_volume, ta.delete_volume],
233: [ta.attach_volume, ta.detach_volume, ta.delete_volume],
234: [ta.delete_volume], 244: [ta.delete_volume], 321: [],
332: [ta.detach_volume, ta.delete_volume],
333: [ta.detach_volume, ta.delete_volume], 334: [],
342: [ta.detach_volume, ta.delete_volume],
343: [ta.detach_volume, ta.delete_volume], 344: [],
3000: [ta.delete_image, ta.create_data_volume_from_image]
}By this way, the model-based testing system can keep running from one stage to another until meeting some pre-defined exit conditions or finding some defect, it can continuously run several days and call APIs tens of thousands times.
Action Selection Strategies
When moving amid stages, the model-based testing system needs to decide what the next operation to perform; the decision maker is called action selection strategy that is a pluggable engine that various selection algorithms can be implemented with different intentions.
Current system has three strategies:
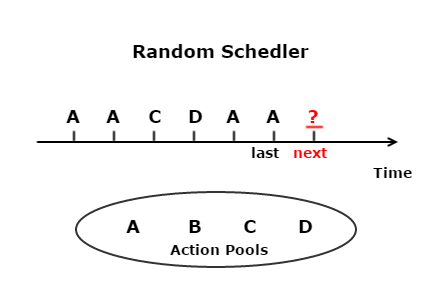
- Random scheduler is the simplest strategy that randomly picks up the next operation from candidates for the current stage. As a straightforward algorithm, the random scheduler may repeat one operation while keep other operations starving; to relieve the issue, we enhance each operation with a weight, so testers can give higher weights to operations they want to test more.
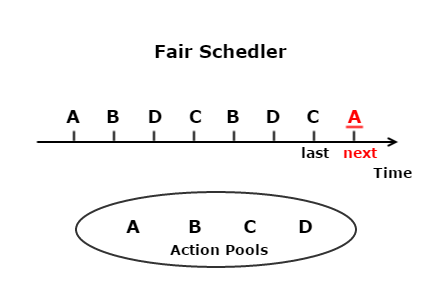
- Fair scheduler is the strategy that every candidate operation is treated equally, compensating random scheduler in the way that every operation has fair chance to be executed, guaranteeing all operations will be tested as long as the testing period is long enough.
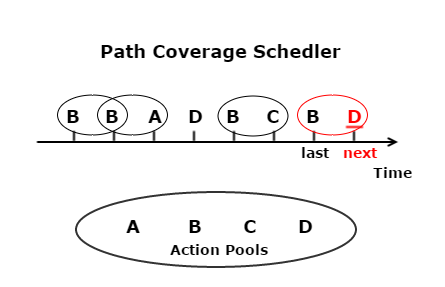
- Path coverage scheduler is the strategy that decides the next operation by historical data; this strategy will memorize operation paths that have been tested, and try to choose the next operation that can form a new operation path; for example, given candidate operations A, B, C, D, if previous operation is B and paths BA, BB, BC all have been tested, the strategy will choose D as the next operation so path BD can be tested.
As mentioned before that action selection strategy is a pluggable engine, every strategy actually derives from class
ActionSelector:
class ActionSelector(object):
def __init__(self, action_list, history_actions, priority_actions):
self.history_actions = history_actions
self.action_list = action_list
self.priority_actions = priority_actions
def select(self):
'''
New Action Selector need to implement own select() function.
'''
pass
def get_action_list(self):
return self.action_list
def get_priority_actions(self):
return self.priority_actions
def get_history_actions(self):
return self.history_actionsAn implementation example of random scheduler is like:
class RandomActionSelector(ActionSelector):
'''
Base on the priority action list, just randomly pickup action.
If need to set higher priority for some action, it just needs to put them
more times in priority_actions list.
'''
def __init__(self, action_list, history_actions, priority_actions):
super(RandomActionSelector, self).__init__(action_list, \
history_actions, priority_actions)
def select(self):
priority_actions = self.priority_actions.get_priority_action_list()
for action in priority_actions:
if action in self.get_action_list():
self.action_list.append(action)
return random.choice(self.get_action_list())Exit Conditions
Before starting the model-based testing system, exit conditions must be set otherwise the system will keep running until a defect is found, or the log files explode hard drive of the testing machine. Exit conditions can be any forms, for example, stopping after running 24 hours, stopping when the system has 100 EIPs created, stopping when there are 2 stopped and 8 running VMs; it's all up to testers to define conditions that can augment the chance of finding defects as big as possible.
Failure Replaying
Debugging a failure found by model-based testing is hard and frustrating; most failures are uncovered by very large
operation sequences that are usually illogical and with huge lines of logs. We used to reproduce failures manually; after
painfully, manually invoking APIs using zstack-cli 200 times following a ~500,000 lines log, we finally realized this
miserable job is humanly impossible. Then we invented a tool that can reproduce a failure by replaying the action log
that records test information purely about APIs.
An action log is like:
Robot Action: create_vm
Robot Action Result: create_vm; new VM: fc2c0221be72423ea303a522fd6570e9
Robot Action: stop_vm; on VM: fc2c0221be72423ea303a522fd6570e9
Robot Action: create_volume_snapshot; on Root Volume: fe839dcb305f471a852a1f5e21d4feda; on VM: fc2c0221be72423ea303a522fd6570e9
Robot Action Result: create_volume_snapshot; new SP: 497ac6abaf984f5a825ae4fb2c585a88
Robot Action: create_data_volume_template_from_volume; on Volume: fe839dcb305f471a852a1f5e21d4feda; on VM: fc2c0221be72423ea303a522fd6570e9
Robot Action Result: create_data_volume_template_from_volume; new DataVolume Image: fb23cdfce4b54072847a3cfe8ae45d35
Robot Action: destroy_vm; on VM: fc2c0221be72423ea303a522fd6570e9
Robot Action: create_data_volume_from_image; on Image: fb23cdfce4b54072847a3cfe8ae45d35
Robot Action Result: create_data_volume_from_image; new Volume: 20dee895d68b428a88e5ec3d3ef634d8
Robot Action: create_volume_snapshot; on Volume: 20dee895d68b428a88e5ec3d3ef634d8Testers can recreate the failure environment by calling the replaying tool:
robot_replay.py -f path_to_action_log
Summary
In this article, we introduced model-based testing system. As being good at uncovering issues of corner cases, the model-based testing system works with integration testing system and system testing system as the foundation of defending ZStack's quality, allowing us to deliver a product with proud confidence.