Storage Model: Primary Storage and Backup Storage
ZStack abstracts storage systems, by their logical functionality, into primary storage and backup storage. A primary storage is a storage pool on which VM volumes locate; a backup storage is the storage that users store image templates and backup volumes and snapshots. Primary storage and backup storage can be physically separate storage systems or the same storage system playing both roles, storage vendors can easily plug in their products by implementing corresponding storage plugins.
Overview
Storage systems in a cloud can be divided into two categories by their logical functionality. One class works as storage pools that store volumes of VMs and will be accessed by running VMs; this kind of storage can be filesystem based that volumes are stored as files, or block storage based that volumes are block devices. In ZStack terms, this sort of storage is called as Primary Storage which can be either network shared storage such as NFS, ISCSI:
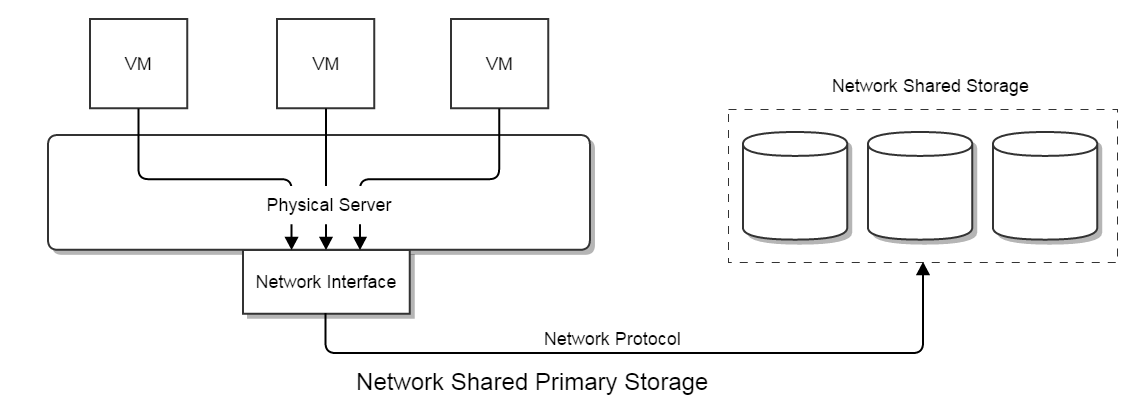
or local storage such as hard drives of physical hosts:
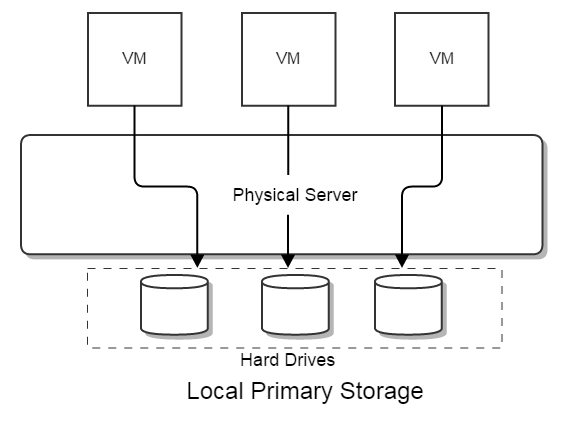
Another class of storage system works as warehouses that store image templates containing operating systems, and that backup volumes and snapshots; this kind of storage can be filesystem based that entities are stored as files, or object-store based that entities are stored as objects. In ZStack terms, this sort of storage is called as Backup Storage that is not directly accessible to VMs, and that can be only network shared storage:
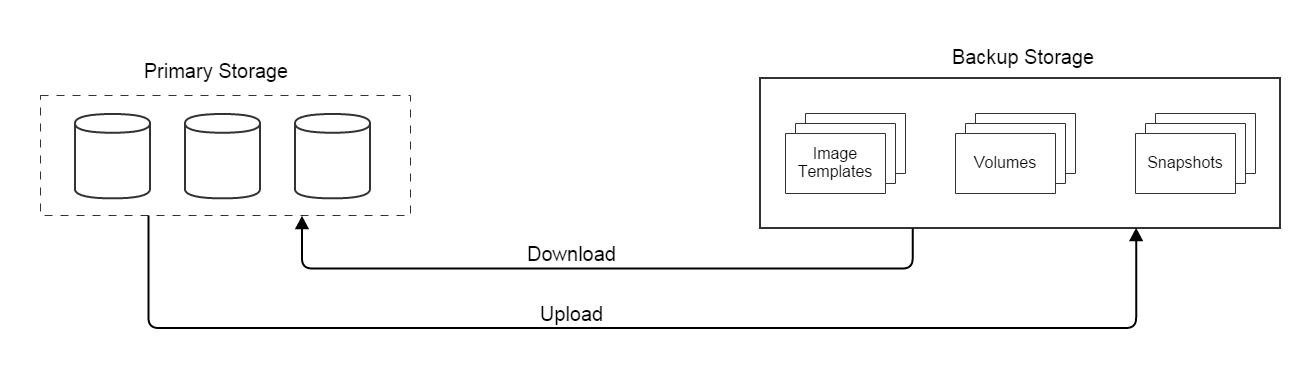
Both primary storage and backup storage are logical concepts, in reality, they can be individual storage systems using totally different protocols, for example, ISCSI primary storage and NFS backup storage, or the same storage system that can play pair roles, for example, ceph, whose block part is competent for primary storage while object part can take the role of backup storage. Storage vendors can easily plug in their storage systems in ZStack by implementing storage plugins, for both primary storage and backup storage.
Implementation inside
Primary storage and backup storage are not working separately; they need to cooperate with each other in order to conduct storage relevant activities. The most important activity is for creating a new VM; when a VM is the first time created on a primary storage, its image template will be downloaded from a backup storage to the image cache of the primary storage; as most hypervisors use a technology called linked clone, once the image template has been downloaded, it works as a base volume for all VMs using the same image template and having the root volume in the same primary storage;
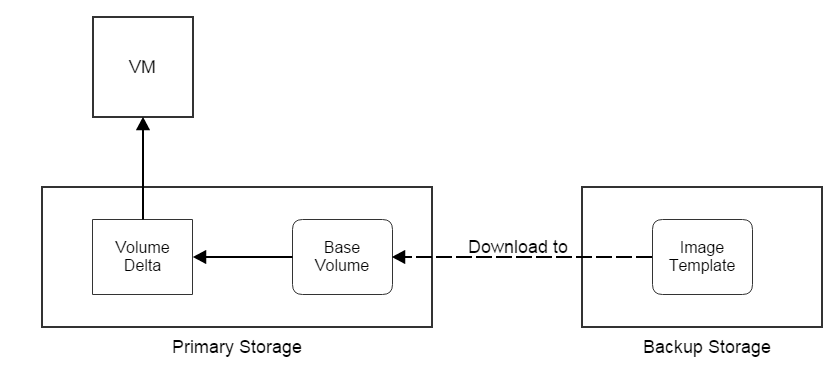
Besides downloading template, primary storage can also upload entities like volumes, snapshots to backup storage; those uploading activities are all backup related; for example, when users backup a data volume, a copy of the data volume will be uploaded to a backup storage as an image template, which can be downloaded to a primary storage later for creating new data volumes.
In the source code, primary storage and backup storage are implemented in different plugins. In terms of complexity, backup storage
is more straightforward because they only deal with own business. The major activities of backup storage are downloading, uploading, and deleting.
A backup storage needs to define protocols that how primary storage download and upload entities, but it doesn't need to know details of
primary storage, because it's responsibility of primary storage to use these protocols to conduct these activities. Besides, backup storage must
implement protocols allowing the image service to register and delete image templates. Similar to all other resources, the backup storage has an abstract base
class BackupStorageBase that has already implemented most generic business logic, vendors only need to implement operations that directly relates to
their backend storage systems, usually by invoking SDK or calling agents.
Primary storage is more complex. The complexity stems from the fact that its business logic is not only backup storage dependent but also hypervisor specific. A primary storage, first of all, must understand protocols of backup storage to download and upload entities; for instance, a NfsPrimaryStorage must know the protocols of SftpBackupStorage, AmazonS3BackupStorage, and SwiftBackupStorage if it plans to support all of them. On the other side, the usages of protocols to the same backup storage vary for different hypervisors; for example, NfsPrimaryStorage can call the KVM agent to download an image template from AmazonS3BackupStorage using s3tool; however, as VMWare has a closed ecosystem, the only way NfsPrimaryStorage does the same thing may have to go through VMWare's SDK. Given those facts, the complexity of primary storage is M x N where M is the number of backup storage and N is the number of hypervisors it supports.
As stated in The Versatile Plugin System, ZStack is a plugin system that every feature is made as a small plugin; a primary storage
needs to define two interfaces to crack the complexity. The first one is a hypervisor backend that deals with activities only related to hypervisors;
for example, NfsPrimaryStorage has an interface NfsPrimaryStorageBackend defined, for each supported hypervisor there will be a concrete class like
NfsPrimaryStorageKVMBackend for KVM. The second one, called PrimaryToBackupStorageMediator, is a hypervisor-to-backup-storage backend that handles activities
involving both hypervisors and backup storage; for example, NfsPrimaryStorage has an implementation NfsPrimaryToSftpBackupKVMBackend supporting SftpBackupStorage for KVM.
It sounds terrible that a primary storage has to implement so many things; however, in reality, a primary storage may not need to support all backup storage for all hypervisors; for example, it is worth nothing supporting SftpBackupStorage for VMWare as VMWare SDK has a fat chance allowing scp a file to its datastore (though it may be doable by bypassing SDK, we don't view it as a reliable way). And the prevailing protocols of network shared storage are not too many, most use cases can be handled once we have NfsPrimaryStorage and IscsiPrimaryStorage in place.
Note: In current ZStack version(0.6), only NfsPrimaryStorage and SftpBackupStorage are implemented.
Summary
In this article, we demonstrated ZStack's storage model. By dividing the storage functionality logically into primary storage and backup storage, ZStack provides a great flexibility that storage vendors can selectively plug in their storage system with different intentions. And with more and more common storage protocols such as NFS, ISCSI, S3, Swift being added as default plugins, users will not worry about they cannot find a proper combination for their existing storage systems.